
Documentaciòn de IREPORTS
Como ya lo había prometido, a continuación un post sobre el diseñador Ireport para JasperReports. Trataré de describir la funcionalidad de este sin que este se vea comprometido con un solo sistema operativo.
OBJETIVO:
INTRODUCCION
¿Qué es Ireport?
Algunas Características

Desarrollo
Para poder ejecutar el Ireport se necesita el SDK 1.5.0 o superior, 256MB de RAM y al menos 20 megas de espacio en disco.
Estructura de los reportes
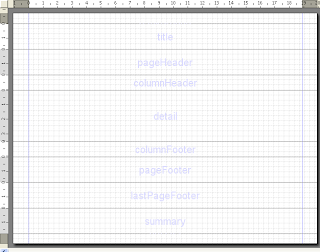
La estructura de los reportes se encuentra dividida por secciones horizontales llamadas "Bandas", las cuales son rellenadas con los datos que requerimos en una posición especifica, es aquí donde se definen las reglas del reporte
Esta divida en 9 bandas, en las cuales se pueden removidas o agregadas en el reporte, por default se muestran:
JRXML y archivos jasper
Un reporte es guardado en un archivo tipo XML el cual cada una de sus secciones se encuentra definido por jasperreport.dtd, es por eso que el archivo fuente tiene la extensión "*.JRXML" el cual contiene la configuración del reporte físicamente, las dimensiones de la pagina entre otras.
Si la compilación de este archivo se realiza de manera correcta genera entre otros un archivo con extensión "Jasper" el cual puede ser interpretado por la JVM.
Elementos y letras
Los elementos contenidos en un reporte pueden ser:
Esta se encuentra en la barra de herramientas

Expresiones dentro del reporte
Las expresiones que se pueden manejar dentro de un reporte son instrucciones en lenguaje Java siempre y cuando el resultado sea un objeto (Que extienda de Object pues).
Entonces desde una expresión se puede referir a parámetros, variables fields y lo que se encuentre definido dentro del reporte, aquí algunas sintaxis:
Además se puede usar Groovy como lenguaje dentro de las expresiones
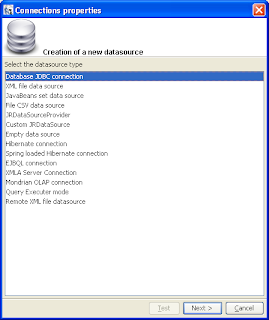
Creación de una conexión con JDBC (Datasources)
Ireport tiene la capacidad de soportar lenguajes de consulta como: SQL, HQL, EJBL, MDX y XPath. Ahora que si no se va a utilizar una consulta a la Base de Datos, no necesitas una consulta dentro del reporte; sino un DATASOURCE
Un datasource es un objeto que itera sobre un record parecido a una tabla. JasperReport provee algunas implementaciones de DataSources que pueden ser envueltas en estructuras de datos genericas como: Arrays o Colecciones de javaBeans, result sets, table models, CSV y archivos XML.
Aquí una lista de datasource y conexiones provistas por Ireport
Plugin para NetBeans
Aqui un tutorial para poder agregar y configurar el plugin necesario para poder trabajar con Ireport desde Netbeans, el ejemplo esta basado en la distro GNU/Linux Ubuntu [2] y aqui otro hecho desde MAC [3].
CONCLUSIÓN
Espero haber logrado los objetivos planeados.
REFERENCIAS
[1] http://jasperforge.org/plugins/project/project_home.php?group_id=83
[2] http://wiki.netbeans.org/Avbravotutorialbasiconetbeansreports
[3] http://wiki.netbeans.org/NBDemoIReport
OBJETIVO:
- Conocer la utilidad de esta
- Tener una perspectiva de manera rápida aunque no definitiva de las cosas que se pueden hacer con Ireport
- Tener una solución bajo la manga
- Que esta guía sea una referencia para alguien en este Cyberespacio
INTRODUCCION
¿Qué es Ireport?
- Diseñador de reportes gráficos muy complejos si así lo requerimos para JasperReports
- Un programa OpenSource (GPL)
- Esta escrito al 100% en Java
- La versión comercial de esta y la que se recomienda para la producción se llama JasperStudio la cual es mantenida por la empresa JasperSoft Corporation
- Esta integrada en la Jasper Bussines Intelligence Suite
- Sitio WEB
Algunas Características
- Categoría: Bussines Intelligence
- Soporte para TrueType
- Manejo de múltiples fuentes de datos como: todas las bases de datos soportadas por JDBC, archivos XML, CSV, Hibernate entre otros…
- Soporta SQL, HQL, EJBQL, MDX y Xpath
- Wizard para la creación de reportes y sub-reportes
- Más de 30 elementos para formatear el reporte (lineas, elipses, TextFields, charts,código de barras, etc.)
- El núcleo de este es una biblioteca llamada JasperReports, la cual fue desarrollada por Teodor Danclu de JasperSoft Corporation
- Los reportes generados se puede pre visualizar y/o exportar en PDF, HTML, RTF, XLS, CSV, TXT y más...
Desarrollo
Para poder ejecutar el Ireport se necesita el SDK 1.5.0 o superior, 256MB de RAM y al menos 20 megas de espacio en disco.
Estructura de los reportes
La estructura de los reportes se encuentra dividida por secciones horizontales llamadas "Bandas", las cuales son rellenadas con los datos que requerimos en una posición especifica, es aquí donde se definen las reglas del reporte
Esta divida en 9 bandas, en las cuales se pueden removidas o agregadas en el reporte, por default se muestran:
- Titulo
- Header de pagina
- Header de columnas
- Detalle
- Pie de columna
- Pie de pagina
- Ultimo pie de pagina
- Sumario

JRXML y archivos jasper
Un reporte es guardado en un archivo tipo XML el cual cada una de sus secciones se encuentra definido por jasperreport.dtd, es por eso que el archivo fuente tiene la extensión "*.JRXML" el cual contiene la configuración del reporte físicamente, las dimensiones de la pagina entre otras.
Si la compilación de este archivo se realiza de manera correcta genera entre otros un archivo con extensión "Jasper" el cual puede ser interpretado por la JVM.
Elementos y letras
Los elementos contenidos en un reporte pueden ser:
- Lineas
- Elipses
- Texto estático
- Texto Dinámico
- Imagenes
- Rectangulos con/sin relleno
- Sub-reportes
- Codigo de Barras
- Graficas
- HyperLink
- etc.
Esta se encuentra en la barra de herramientas

Expresiones dentro del reporte
Las expresiones que se pueden manejar dentro de un reporte son instrucciones en lenguaje Java siempre y cuando el resultado sea un objeto (Que extienda de Object pues).
Entonces desde una expresión se puede referir a parámetros, variables fields y lo que se encuentre definido dentro del reporte, aquí algunas sintaxis:
$F{field} Especifica el nombre de un Field
$V{variable} Especifica el nombre de una Variable
$P{parametro} Especifica el nombre de un Parametro
$P!{parametro} Una sintaxis especial usada en una consulta SQL, indica que
el parametro no debe de ser tratado como un valor por ejemplo:
SELECT * FROM empleado $P!(ID)}
Que equivale a decir dado que ID=5
SELECT *FROM empleado WHERE ID = 5Además se puede usar Groovy como lenguaje dentro de las expresiones
Creación de una conexión con JDBC (Datasources)
Ireport tiene la capacidad de soportar lenguajes de consulta como: SQL, HQL, EJBL, MDX y XPath. Ahora que si no se va a utilizar una consulta a la Base de Datos, no necesitas una consulta dentro del reporte; sino un DATASOURCE
Un datasource es un objeto que itera sobre un record parecido a una tabla. JasperReport provee algunas implementaciones de DataSources que pueden ser envueltas en estructuras de datos genericas como: Arrays o Colecciones de javaBeans, result sets, table models, CSV y archivos XML.
Aquí una lista de datasource y conexiones provistas por Ireport

Plugin para NetBeans
Aqui un tutorial para poder agregar y configurar el plugin necesario para poder trabajar con Ireport desde Netbeans, el ejemplo esta basado en la distro GNU/Linux Ubuntu [2] y aqui otro hecho desde MAC [3].
CONCLUSIÓN
Espero haber logrado los objetivos planeados.
REFERENCIAS
[1] http://jasperforge.org/plugins/project/project_home.php?group_id=83
[2] http://wiki.netbeans.org/Avbravotutorialbasiconetbeansreports
[3] http://wiki.netbeans.org/NBDemoIReport
Reportes desde SCCM con Ireport
Hace mucho q no les doy una mano para SCCM 2007. Hoy voy a explicarles en simples pasos como podemos programar reportes automáticos con SCCM 2007 SP2. Esto lo podemos realizar gracias a Reporting Services que viene con MsSQL 2005. Si no tenemos este feature instalado debemos instalarlo en el servidor. Quizas tengan algún inconveniente al tratar de correr el instalador del SQL 2005 nuevamente pero tocando un poco la registry sale andando. Prometo buscar eso y postearlo cuando lo encuentre... lo perdí.Les paso el link de los prerrequisitos: link.
Deben montar el cd de SQL 2005 en el servidor o la version q hayan instalado. En ni caso particular trabaje con MsSql 2005 SP2 x64 y SCCM 2007 SP2. Deben pasar los prerrequisitos.

Importante, si ya poseen alguna base les va a pedir que corran el setup con una línea desde el cmd y el parámetro: SKUUPGRADE=1. Esto upgradeara la base de datos en cuestión.
 Una vez pasado los chequeos debemos seleccionar Reporting Services para instalar y seguir los pasos del Wizard. Más datos en este link.
Una vez pasado los chequeos debemos seleccionar Reporting Services para instalar y seguir los pasos del Wizard. Más datos en este link.Una vez instalado el feature en el server deben correr el Wizard para configurarlo: "Reporting Services Configuration". Aquí les va a tirar un error poco común que se van a volver locos buscándole solución pero lo que ocurre es q al tener instalado el SP2 del MSSQL el cd quiere instalar una version anterior de Reporting Services. Entonces, antes de configurarlo debemos correr el instalador del SP2 nuevamente para que quede todo actualizado. Una vez corrido el SP2 ahora si podemos correr el Wizard de configuración sin problemas. Entre otras cosas se crean los sites para los reportes, se definen los usuarios, se crea la base de datos y otro par de temas como configuración del servidor de smtp para mandar los emails.
Luego, una vez terminado de configurar debemos instalar el role en nuestro site de SCCM. Elegimos el server y lo instalamos con el wizard. Nada dificil.

Una vez instalado podremos ingresar al apartado de Reporting Services debajo de Reports ya conocido y habilitado por default.

Allí debemos elegir el servidor al cual conectarnos y con un click derecho podremos importar desde Reports todos los reportes que ya conocemos para poder ponerlos en el site de Reporting Services y poder programarlos. Se pueden configurar totalmente, fecha, iteración, permisos, etc.
Este es un ejemplo de como se vería el site de Reporting Services de nuestro Site SCCM.

