Tomado de:
http://www.avast.com/esp/update_avast_4_vps.html

martes, julio 28, 2009
WebService
Tomado de:
http://wiki.gxtechnical.com/commwiki/servlet/hwiki?WebService
http://wiki.gxtechnical.com/commwiki/servlet/hwiki?WebService
SOAP (Simple Object Access Protocol). Protocolo de comunicación, basado en XML, que sirve para la invocación de los servicios Web a través de un protocolo de transporte, como HTTP. Consta de tres partes: una descripción del contenido del mensaje, unas reglas para la codificación de los tipos de datos en XML y una representación de las llamadas RPC para la invocación y respuestas generadas por el Web Service.
WEB SERVICES.- Los Web Services son pequeños programas formados por varios componentes que permiten ser publicados en directorios e invocados para su ejecución por otros programas vía http, generando una respuesta en XML.
Quizás la ventaja principal de los Web Services es que se trata de un estándar aceptado y que, a diferencia de otras tecnologías de integración, posibilitan la compartición de funcionalidades entre sistemas heterogéneos de forma transparente, mediante el intercambio de datos vía XML. Para este intercambio el único requisito es establecer conexiones TCP/IP posibilitando la comunicación http entre los sistemas.
WSDL: WEB SERVICES DESCRIPTION LANGUAJE
WSDL es un lenguaje basado en XML que se utiliza para describir un Web Services. Un archivo con formato WSDL provee información de los distintos métodos (operaciones) que el WebServices brinda, muestra cómo accederlos y que formatos deben de tener los mensajes que se envían y se reciben.
Es como un contrato entre el proveedor del servicio y el cliente, en el cual el proveedor se compromete a brindar ciertos servicios solo si el cliente envía un requerimiento con determinado formato.
Es el documento principal a lo hora de documentar un Web Services, pero puede no ser el único. En la mayoría de los casos es conveniente que este acompañado por un documento escrito en lenguaje natural que brinde información de que es lo que hace cada uno de los métodos brindados por el Web Services.
En forma resumida podríamos decir que un archivo WSDL describe lo siguiente:
· Mensajes que el servicio espera y mensajes que el servicio responde.
· Protocolos que el servicio soporta.
· A donde mandar los mensajes.
Tomado de: http://www.gxtechnical.com/gxdlsp/pub/iehelp.htm?GeneXus/Internet/TechnicalPapers/Web_Services.htm
Links interesantes:
Conceptos Generales de Web Services - Manual de Consulta Rápida
Conceptos Generales de Web Services - Manual de Consulta Rápida
Manual de Consulta Rápida para el Desarrollo de WebServices con Genexus 9.0, Base de Datos SQL Server y Generador .NET
OBJETIVO
Presentar al detalle todos los pasos que se deben seguir para la elaboración de un Webservice y consumirlo.
Este manual esta orientado para toda aquella persona que recién se inicia el la elaboración de WebServices con Genexus.
CONCEPTOS GENERALES
Aquí se detallan las definiciones principales de web services, en general.
WEB SERVICES CON GENEXUS
Aquí hay un documento en el que se explica cómo estos conceptos arriba definidos se hallan en GeneXus: WebServicesWithGX
EJEMPLO DE WEB SERVICES
Un ejemplo detallado: Webservices paso a paso
Mas Informacion:
http://www.gxtechnical.com/gxdlsp/pub/iehelp.htm?GeneXus/Internet/TechnicalPapers/Web_Services.htm
Todo esto es un modelo de mensajes request/response con una forma de describir un conjunto de métodos y pasarle a los mismos parámetros. Esto parece la base del protocolo RPC y de hecho es el uso más común de SOAP. El potencial es entregar esto sobre Internet utilizando HTTP para realizar comunicaciones entre organizaciones permitiendo realizar comunicaciones entre aplicaciones con diferente plataforma, sistema operativo y lenguaje de programación.
Un ejemplo detallado: Webservices paso a paso
Mas Informacion:
http://www.gxtechnical.com/gxdlsp/pub/iehelp.htm?GeneXus/Internet/TechnicalPapers/Web_Services.htm
Web Services
Abstract
En los últimos tiempos ha surgido con mucha fuerza el concepto de ‘web services’, incluso afirmándose que el mismo cambiaría la forma de programar las aplicaciones orientadas a Internet hacia una arquitectura orientada a servicios. Todo esto se ha visto potenciado luego del anuncio de Microsoft de su nueva estrategia .NET que está basada en el modelo de web services.
Este documento describe que son los web services y como es la arquitectura general del modelo, adicionalmente se provee una introducción de los estándares en los cuales se basa este modelo como ser SOAP, WSDL y UDDI.
¿Qué es un web service?
Un web service es una aplicación que puede ser descripta, publicada, localizada e invocada a través de una red, generalmente Internet. Combinan los mejores aspectos del desarrollo basado en componentes y la Web.
Al igual que los componentes, los web services son funcionalidades que se encuentran dentro de una caja negra, que pueden ser reutilizados sin preocuparse de cómo fueron implementados. A diferencia de la actual tecnología de componentes, no son accedidos por medio de protocolos específicos del modelo de objetos como ser RMI, DCOM o IIOP; sino que son accedidos utilizando protocolos web como ser HTTP y XML.
La interface de los web services esta definida en términos de los mensajes que el mismo acepta y retorna, por lo cual los consumidores de los web services pueden ser implementados en cualquier plataforma y en cualquier lenguaje de programación, solo tiene que poder crear y consumir los mensajes definidos por la interface de los web services.
El modelo de web services.
La arquitectura básica del modelo de web services describe a un consumidor, un proveedor y ocasionalmente un corredor (broker). Relacionados con estos agentes están las operaciones de publicar, encontrar y enlazar.
La idea básica consiste en que un proveedor publica su servicios en un corredor, luego un consumidor se conecta el corredor para encontrar los servicios deseados y una vez que lo hace se realiza un lazo entre el consumidor y el proveedor.
Cada entidad puede jugar alguno o todos los roles.

Por todo lo anterior hay ciertos requerimientos a la hora de desarrollar o consumir un web services:
- Una forma estándar de representar los datos.
XML es la opción obvia para este requerimiento.
- Un formato común y extensible de mensajes.
SOAP es el elegido en este caso; SOAP es un protocolo liviano para el intercambio de información. Más adelante en este documento lo veremos con más detalle.
- Un lenguaje común y extensible para describir los servicios.
La opción en este caso es WSDL. Es un lenguaje basado en XML desarrollado en forma conjunta por IBM y Microsoft. Lo veremos con más detalle mas adelante en este documento.
- Una forma de descubrir los servicios en Internet.
UDDI se utiliza en este caso; el mismo especifica un mecanismo para publicar y localizar los servicios por parte de los proveedores y consumidores respectivamente. Se verá con más detalle mas adelante en este documento.
Ventajas y retos.
Los web services apuntan a ser la piedra fundamental de la nueva generación de sistemas distribuidos. Estos son algunos puntos para fundamentar esta afirmación:
- Interoperabilidad:
Cualquier web service puede interactuar con otro web service. Como los web services pueden ser implementados en cualquier lenguaje, los desarrolladores no necesitan cambiar sus ambientes de desarrollo para producir o consumir web services.
- Ubicuidad:
Los web services se comunican utilizando HTTP y XML. Por lo tanto cualquier dispositivo que soporte estas tecnologías pueden implementar o acceder web services. Muy pronto estarán presentes en teléfonos, autos e incluso máquinas expendedoras, las que avisarán a la central cuando el stock sea menor al indicado.
- Encapsular reduce la comlejidad
Todos los componentes en un modelo de web services son web service. Lo importante es la interface que el servicio provee y no como esta implementado, por lo cual la complejidad se reduce.
- Fácil de utilizar:
El concepto detrás de los web services es fácil de entender, incluso existen toolkits de vendedores como IBM o Microsoft que permiten a los desarrolladores crear web services en forma rápida y fácil.
- Soporte de la Industria:
Todos las empresas de software importantes soportan SOAP, e incluso están impulsando el desarrollo de web services. Por ejemplo la nueva plataforma de Microsoft .NET esta basada en web services, haciendo muy simple el desarrollo de los mismos que luego podrían ser consumidos por un web service desarrollado utilizando VisualAge de IBM y viceversa.
A la vez hay ciertos retos técnicos que los web services tienen que sortear para poder tener éxito. Muchos de estos retos están relacionados con el ambiente abierto en el que tienen que sobrevivir. Estos son algunos de esos puntos:
· Descubrimiento:
¿Como un web service se anuncia para ser descubierto por otro servicio? ¿Qué pasa si el servicio se cambio o se movió luego de ser anunciado?
WSDL y UDDI son dos nuevos estándares que manejan este punto.
· Confiabilidad:
Algunos web services son más confiables que otros. ¿Cómo puede ser medida esa confiabilidad y comunicada? ¿Qué pasa cuando un web service esta off-line en forma temporaria? ¿Localizamos y utilizamos un servicio alternativo brindado por otra empresa o esperamos a que el servicio este de nuevo on-line?
· Seguridad:
Muchos web services son publicados para ser utilizados sin ninguna restricción, pero muchos otros van a necesitar autenticación para que los utilicen solo los usuarios autorizados. ¿Cómo autentifica a los usuarios un web service? ¿Lo hace a nivel del método que lo implementa o utiliza otro web service para realizar la autenticación?
· Responsabilidad
En caso de que el web service no sea de acceso libre, ¿Cómo puedo definir cuantas veces un consumidor puede acceder al web service una vez contratado? ¿Cómo se cobra su uso? ¿Cómo se indica que un servicio ya no esta más en línea?
Tecnologías asociadas
El modelo de web services está basado en ciertas tecnologías emergente que es el resultado del trabajo de varias compañías y organizaciones entre las cuales se destacan IBM y Microsoft.
Estas tecnologías son SOAP, WSDL y UUDI.
SOAP (Simple Object Access Protocol)
SOAP es un protocolo para el intercambio de información en un ambiente descentralizado y distribuido. Es el protocolo más utilizado para realizar el intercambio de información en el modelo de web services.
Esta basado en XML y potencialmente puede ser utilizado en combinación con una variedad de protocolos de comunicación, siendo el más utilizado HTTP. Por lo tanto se utiliza HTTP para transportar la información, y XML para representar la misma.
El protocolo completo se puede encontrar en http://www.w3.org/TR/soap
El modelo de comunicación de SOAP
El modelo de comunicación de SOAP es muy similar al de HTTP. Un cliente hace un requerimiento (request), el servidor que esta escuchando los requerimientos lo atiene y responde (response) brindando la información solicitada o enviando un mensaje de error en caso de que el requerimiento no haya sido válido.
El mensaje SOAP consiste en un elemento envelope SOAP obligatorio, un cabezal SOAP opcional y un cuerpo SOAP obligatorio como un documento XML. El cabezal SOAP es utilizado para definir información acerca del requerimiento, mientras que el cuerpo SOAP contiene el método llamado y los parámetros con los que se llama al mismo.
 |
Todo esto es un modelo de mensajes request/response con una forma de describir un conjunto de métodos y pasarle a los mismos parámetros. Esto parece la base del protocolo RPC y de hecho es el uso más común de SOAP. El potencial es entregar esto sobre Internet utilizando HTTP para realizar comunicaciones entre organizaciones permitiendo realizar comunicaciones entre aplicaciones con diferente plataforma, sistema operativo y lenguaje de programación.
A continuación se muestra un mensaje SOAP embebido en un request HTTP:

Este ejemplo invoca al servicio StockQuote llamando al método GetLastTradePrice con el símbolo DIS por parámetro.
Este es la respuesta al requerimiento anterior, el cual retorna el precio de la acción solicitada:
 |
Si usted quedo asustado por la aparente complejidad del protocolo SOAP pensando lo engorroso que sería armar los mensajes de requerimiento y parsear los mensajes de respuesta despreocúpese; la mayoría de los lenguajes de programación proveen o proveerán soporte para realizar esto. La idea fundamental consiste en utilizar algún objeto al cual se le brinda un WSDL y se le indica que método se quiere llamar y con que parámetros. Esto arma en tiempo de ejecución el mensaje SOAP, lo manda y parsea el resultado adjudicándoselo a alguna variable en forma trasparente para el usuario como si hubiera hecho un call común.
WSDL: Web Services Description Language
WSDL es un lenguaje basado en XML que se utiliza para describir un Web Services. Ha sido suministrado por la W3C por estandarización.
Un archivo con formato WSDL provee información de los distintos métodos (operaciones) que el Web Services brinda, muestra cómo accederlos y que formatos deben de tener los mensajes que se envían y se reciben. Es como un contrato entre el proveedor del servicio y el cliente, en el cual el proveedor se compromete a brindar ciertos servicios solo si el cliente envía un requerimiento con determinado formato. Es el documento principal a lo hora de documentar un Web Services, pero puede no ser el único. En la mayoría de los casos es conveniente que este acompañado por un documento escrito en lenguaje natural que brinde información de que es lo que hace cada uno de los métodos brindados por el Web Services así como también ejemplos, por ejemplo, de los mensajes SOAP que espera y responde el servicio.
En forma resumida podríamos decir que un archivo WSDL describe lo siguiente:
· Mensajes que el servicio espera y mensajes que el servicio responde.
· Protocolos que el servicio soporta.
· A donde mandar los mensajes.
Formato de un archivo WSDL:
A continuación se muestra como es el formato básico de un archivo WSDL. La especificación completa de este lenguaje se puede encontrar en http://www.w3.org/TR/wsdl.html
Un archivo con formato WSDL básicamente contiene los siguientes elementos:
Type: Describe los tipos no estándar usados por los mensajes (Message).
Message: Define los datos que contienen los mensajes pasados de un punto a otro.
PortType: Define una colección de operaciones brindadas por el servicio. Cada operación tiene un mensaje de entrada y uno de salida que se corresponde con algún Message antes definido.
Binding: Describe los protocolos que se utilizan para llevar a cabo la comunicación en un determinado PortType; actualmente los protocolos soportados son SOAP, HTTP GET, HTTP POST y MIME, siendo SOAP el más utilizado.
Port: Define una dirección (URL) para un determinado Binding
Service: Define una colección de Ports.
El siguiente es un ejemplo de archivo WSDL:
El mismo define dos mensajes (Simple.foo y Simple.fooResponse), luego define un método llamado “foo” el cual recibe el mensaje Simple.foo y retorna el mensaje Simple.fooResponse. A continuación se define un binding para el método foo asociándolo con el protocolo SOAP. Por último se da una URL física que implementa lo antes descrito.

Interfase e implementación
La estructura básica de archivo con formato WSDL podría ser dividido en dos partes lógicas: la interfase del servicio, y la implementación del mismo.
Esta división lógica divide los elementos de la siguiente forma:
Interface del servicio:
Type, Message, PortType, Binding.
Contiene una definición abstracta y reusable del servicio que puede ser instanciada y referenciada por distintos proveedores del mismo.
Implementación del servicio:
Port, Service.
Contiene una implementación de una determinada Interface del servicio.
A partir de esta división lógica se puede definir por medio de una Interfase del servicio una estándar para realizar, por ejemplo, ordenes de compras que puede ser reutilizada e implementada por todas las empresas, sin tener que redefinir cada una de ellas la interfase.
Si al igual que con SOAP se siente preocupado por la complejidad de los archivos WSDL de nuevo despreocúpese; la mayoría de los lenguajes de programación proveen o proveerán herramientas para generar en forma automática el archivo WSDL a partir de un determinado método o función.
UDDI (Universal Description, Discovery and Integration).
UDDI (www.uddi.org) es un proyecto inicialmente propuesto por Ariba, Microsoft e IBM; es un estándar para registrar y descubrir web services. La idea es que las distintas empresas registran su información acerca de los web services que proveen para que puedan ser descubiertas y utilizadas por potenciales usuarios.
La información es ingresada al registro de empresas UDDI, un servicio lógicamente centralizado, y físicamente distribuido a través de múltiples nodos los cuales replican su información en forma regular. Una vez que una empresa se registra en un determinado nodo del registro de empresas UDDI la información es replicada a los otros nodos y queda disponible para ser descubierta por otras empresas.
El esquema UDDI
El modelo de información base utilizado por los registros UDDI es definido en un esquema XML. Este esquema define cuatro tipos básicos de información, cada uno de los cuales proveen la clase de información que un usuario necesita saber para utilizar un web service de otra empresa.
Los cuatro tipos de información son:
· Información del negocio.
Este tipo de información esta definido en el elemento businessEntity. Contiene información de la empresa, como ser su nombre, los contactos, el tipo de empresa, etc.
· Información del servicio.
Dentro del elemento businnessEntity se encuentran los elementos businessServices, estos elementos contienen información sobre web services generalmente agrupados por procesos de negocio o categorías de servicios.
· Información del enlace (binding).
Dentro de cada elemento businessServices se encuentran los elementos bindingTemplate. Cada uno de ellos brinda una dirección fisica para hacer contacto con los servicios descriptos anteriormente.
· Información sobre las especificaciones del servicio.
Cada bindingTemplate tiene asociado un tModel, el cual brinda informacíon sobre las especificaciones del servicio, por ejemplo, como tienen que ser los mensajes que el servicio espera y responde, etc.
Un tModel puede ser asociado con elementos bindingTemplate de distintas empresas que brindan la misma especificaión del servicio. Utilizando entonces los tModels se pueden encontrar todas las empresas que brindan tal servicio.

Por más información sobre el esquema UDDI:
http://www.uddi.org/pubs/ProgrammersAPI_v2.pdf
API UDDI
El acceso al registro UDDI, ya sea para realizar búsquedas o para ingresar o modificar un registro, se puede realizar a través de una página web que implemente el acceso o utilizando ciertas interfaces (web services) que provee la especificación de UDDI. Estas interfaces están descriptas en una API, que puede ser dividida en dos partes lógicas, la API de consultas y la API de publicación.
Por más información sobre la API UDDI: http://www.uddi.org/pubs/ProgrammersAPI_v2.pdf
Un ejemplo
Las formas en que se puede realizar negocios utilizando web services es muy variada. El consumidor podría pagar por utilizar los servicios brindados por un proveedor, o el proveedor podría pagar para que aparezcan los servicios que él ofrece en un determinado consumidor, o incluso existen casos en los cuales ni el consumidor ni el proveedor pagan por consumir o proveer los servicios en forma respectiva. Este es el caso que se presenta a continuación.
El ejemplo es tomado de la vida real y es sobre la compañía aérea Southwest. En su portal http://www.southwest.com/ , esta compañía aérea permite hacer reservas de boletos, pero además como valor agregado a los clientes permite hacer reservas de hoteles y reservas de alquileres de autos. Los datos para poder realizar estas reservas están tomados de web services que brindan los distintos hoteles y rentadoras de autos.
Este es un ejemplo de uso de web services en el cual ni el consumidor ni los proveedores pagan; a ambos le sirve este intercambio ya que la compañía de aviones le brinda un valor agregado a sus clientes, y los hoteles y rentadoras de autos están expuestos a ser contratos por potenciales clientes. Es más, estas empresas no publicaron sus servicios para que fueran exclusivamente utilizados por la compañía aérea, sino que los mismos pueden ser descubiertos y utilizados por cualquier empresa que los necesite.
Claramente se muestra en este ejemplo el gran poder de los web services, y la ventaja que tendrán las empresas que los sepan utilizar en forma adecuada con respecto a las otras. Imagínese en este caso si usted fuera a reservar boletos de avión y pudiera elegir por una compañía que además de reservar los boletos le permitiera hacer la reserva de hotel, y otra que no; ¿por cual haría la reserva? Por otro lado imagine que usted es dueño de una rentadora de autos y sabe que su competencia esta brindando sus servicios en un portal de una compañía aérea y usted no, ¿qué haría?.
martes, julio 21, 2009
Sobre la Traduccion del OpenErp
Tomado de:
http://code.google.com/p/tinyerp-community/wiki/Traduccion_es_ES
Traduccion_es_ES
Comentarios y debate sobre la traducción de OpenERP al castellano (España)
Volver a la página de traducciones
INTRODUCCIÓN
GUIA DE ESTILO
- account -> cuenta, contabilidad
- account chart -> plan de cuentas
- account move -> asiento (o apunte)
- account move line -> movimiento, mov. (o partida)
- account owner -> titular de la cuenta
- amount -> importe
- assignation -> asignación
- attendances -> servicios
- balance -> balance o saldo
- balance -> saldo pendiente (en formas de pago)
- balance sheet -> balance
- bank statement -> extractos bancarios
- BOM -> LdM (Bill of Material -> Lista de Materiales, hay que mantenerlo abreviado)
- case -> caso
- chart -> gráfico (de pastel, de barras, de líneas), resumen (chart muestra muchas veces tablas de resumen)
- chart of accounts -> plan contable
- company -> compañía (es la propia empresa)
- credit -> haber
- credit balance -> saldo acreedor
- custom -> personalizado
- dashboard -> tablero
- deadline -> fecha límite
- debit -> debe
- debit balance -> saldo deudor
- default -> por defecto
- deferral -> cierre
- done -> realizado
- email -> email, correo electrónico
- event -> evento
- file -> archivo
- fiscal year -> ejercicio fiscal
- follow-up -> seguimiento
- general ledger -> libro mayor
- goods -> material
- grid -> tabla
- helpdesk -> helpdesk (¿Mejor traducirlo como centro de soporte?)
- history -> historial
- HR -> RRHH
- in progress -> en proceso
- item -> detalle, elemento
- location -> ubicación
- lot -> lote
- meeting -> reunión
- Ok -> Aceptar
- opened -> abierto
- order -> orden o pedido. Una orden o pedido puede estar, por ejemplo, en estado borrador (presupuesto), confirmada (comanda), enviada (albaran), facturada (factura))
- sale order -> pedido de venta
- purchase order -> pedido de compra
- manufacturing order -> orden de fabricación
- order point -> punto de pedidos?
- packing -> paquete
- partner -> empresa
- partner code, customer ref -> CIF/NIF
- payable -> deber
- payable -> a pagar (en tipos de cuenta)
- procurement -> abastecimiento
- purchase -> compra
- quotation -> presupuesto
- receivable -> haber
- receivable -> a cobrar (en tipos de cuenta)
- refund -> factura de abono
- reordering Policy -> política de reabastecimiento
- report -> informe
- repository -> biblioteca de módulos
- request -> solicitud
- role -> rol
- routing -> hoja de ruta
- routing -> proceso productivo
- salesman -> comercial (antes era vendedor)
- sale -> venta
- scheduling -> planificación
- sequence -> secuencia
- setup -> configuración
- shorcut -> Acceso rápido (menús) / Abreviación (empresas)
- spread -> margen, extensión
- state of mind -> grado de satisfacción
- stock -> stock
- structure -> estructura, despiece
- subscription -> documentos periódicos, asientos periódicos
- tax -> impuesto
- term -> forma de pago
- timesheet -> hoja de servicios, hoja de asistencia
- total -> total
- tracking -> tracking (¿Es mejor rastreo?)
- track -> track (¿Es mejor rastreo?)
- tree -> árbol
- UOM -> UdM (Unit of Manufacturing -> Unidad de Manufacturación, hay que mantenerlo abreviado)
- UOS -> UdV (Unit of Sell -> Unidad de Venta, hay que mantenerlo abreviado)
- untaxed amount -> base imponible
- VAT -> IVA
- wage -> salario
- wizard -> asistente
- workcenter -> centro de producción
- workflow -> flujo de trabajo
- write-off -> desajuste
- zip -> C.P. (Código Postal abreviado)
ACCIONES (verbos en infinitivo)
- asigne -> asignar
- cancel -> cancelar
- close -> cerrar
- compute -> calcular
- confirm -> confirmar
- create -> crear
- open -> abrir
- pack -> empaquetar
- pay -> pagar
- print -> imprimir
- run -> ejecutar
- select -> seleccionar
- send -> enviar
- sign in -> registrar entrada
- sign out -> registrar salida
Traducciones referentes al método Scrum
Términos consensuados y incorporados el 3-4-2008
MENÚ PARTNERS
Credit Limit está traducido como Límite Haber. Propongo utilizar Crédito o Crédito concedido
State of Mind está traducido como Estados de satisfacción. Propongo utilizar Grado de satisfacción
Account owner está traducido como Dueño de la cuenta. Propongo utilizar Titular de la cuenta
MENÚ SALES MANAGEMENT
Untaxed Amount está traducido como Importe sin impuestos. Propongo utilizar Base imponible
El estado In progress está traducido como En progreso. Propongo utilizar En proceso
Packing name está traducido como Nombre del paquete. Propongo utilizar Nº albarán o Ref albarán
Términos propuestos
Sep 20, 2008
jueves, julio 16, 2009
Como configurar Conexion Remota en SQL Server 2005
Tomado de:
http://www.linhadecodigo.com.br/ArtigoImpressao.aspx?id=1260
Pagina Original:
http://www.linhadecodigo.com.br/Artigo.aspx?id=1260&pag=2
http://www.linhadecodigo.com.br/ArtigoImpressao.aspx?id=1260
Pagina Original:
http://www.linhadecodigo.com.br/Artigo.aspx?id=1260&pag=2
| Como configurar Conexão Remota no SQL Server 2005 |
| Publicado em: 02/03/2007 |
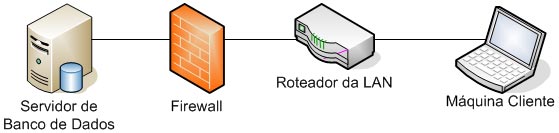
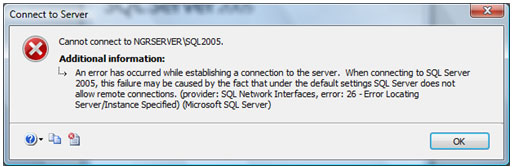
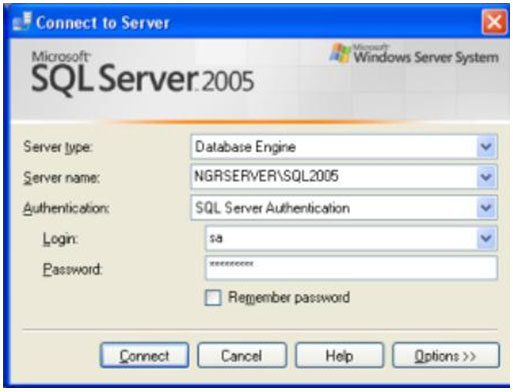
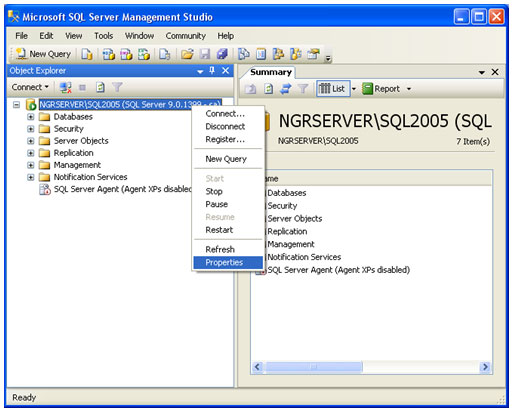
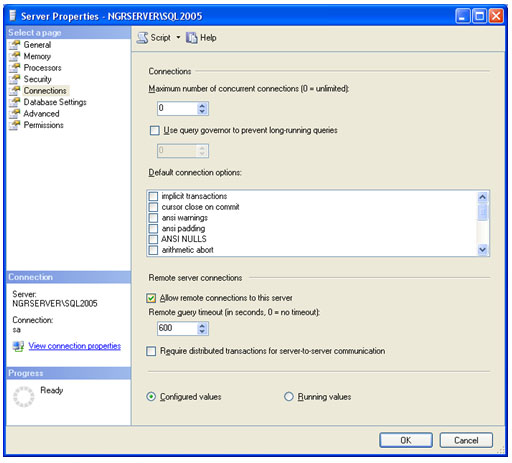
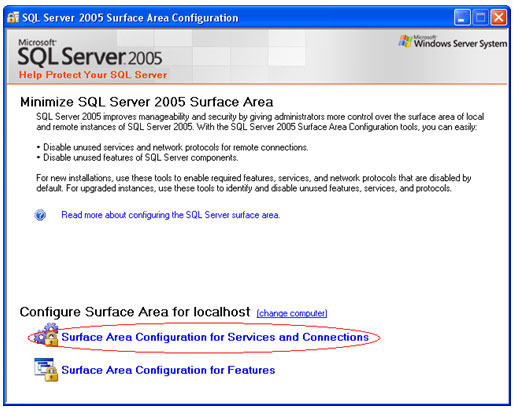
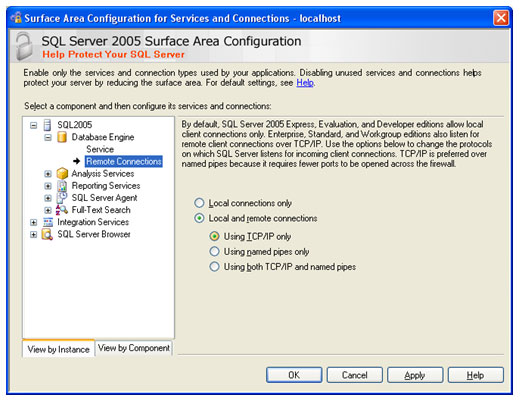
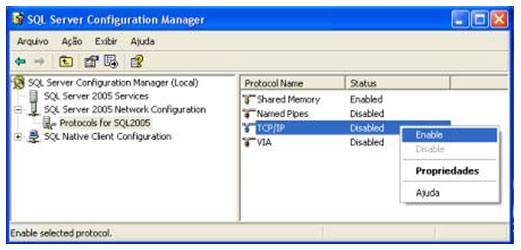
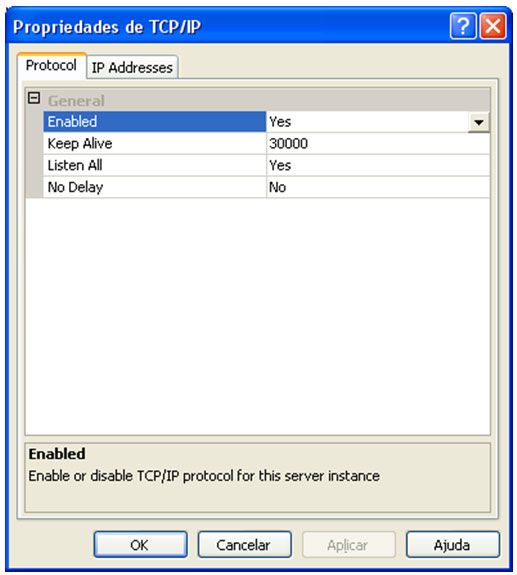
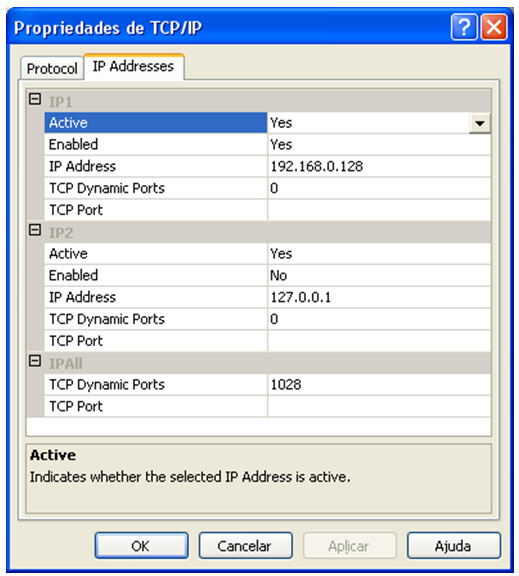
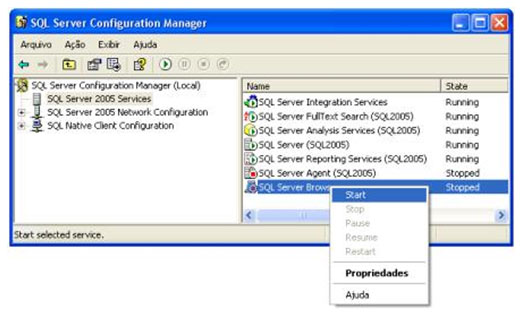
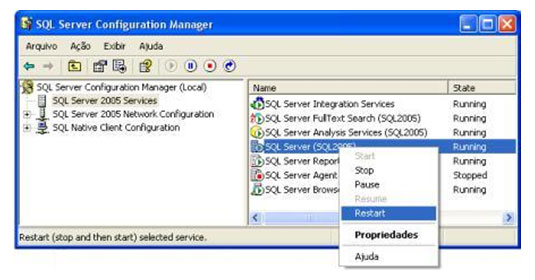
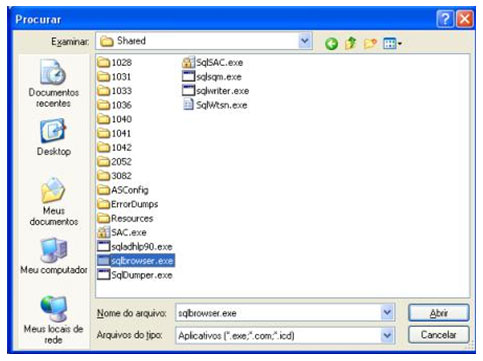
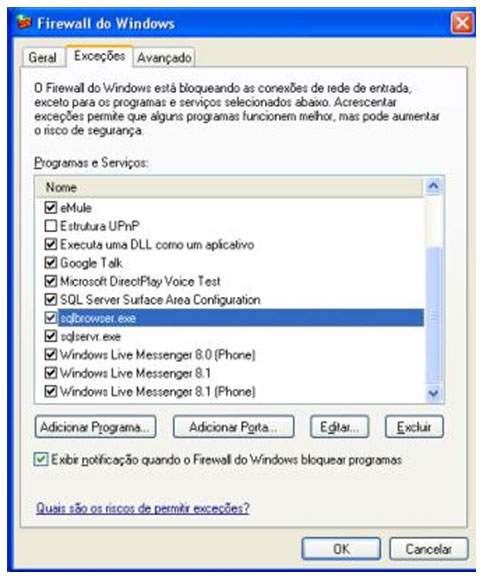
| Muitos casos de problemas com conexão ao servidor de Banco de Dados ocorrem por uma limitação que o SQL Server 2005 possui por padrão. Esta configuração de segurança que vem padronizada no SQL pode ser alterada facilmente. Neste artigo, será apresentada uma maneira de como solucionar este problema rapidamente. Para simular o ambiente, duas máquinas serão utilizadas. Uma será o Servidor de Banco de Dados, e a outra será a máquina cliente. No diagrama abaixo, existe uma arquitetura de exemplo para ilustrar a solução. O nome do Servidor de Banco de Dados é NGRSERVER e a máquina cliente se chama NOTEBOOK. A instância do SQL Server 2005 que está no servidor é chamada de SQL2005. Vamos ao que interessa. Ao tentar acessar o Servidor de Banco de Dados com sua configuração padrão, uma mensagem de erro é apresentada. Esta mensagem diz que ocorreu um erro enquanto estabilizava uma conexão com o servidor, esta falha pode ser pelo fato da configuração padrão do SQL Server não permitir conexões remotas. A solução deste problema é resolvida em alguns passos: 1. Permitir conexões remotas à instância do SQL Server que será acessada de outro computador; Estes passos garantem a conexão remota do SQL Server. Abaixo cada passo é explicado detalhadamente. Passo 1: Para permitir que computadores acessem instâncias do SQL Server em outra máquina, a primeira coisa a ser feita é uma configuração na instância que receberá as conexões remotas, no nosso caso, o SQL2005 no servidor NGRSERVER. Para fazer isso, conecte-se localmente na instância do servidor, clique com o botão direito na instância conectada e aponte o mouse para Properties. Depois de acessar a tela das propriedades da instância do SQL Server, escolha, no menu da esquerda, a opção Connection. A parte direita da tela será referente à Connection, procure a opção Allow remote connection to this server. Deixe esta opção marcada. Clique em OK. A conclusão deste procedimento passa a garantir que a instância do SQL Server poderá receber conexões remotas, mas este não é o único passo a ser cumprido. Mais alguns passos devem ser seguidos para a conclusão da tarefa. Passo 2: Para permitir que o protocolo TCP/IP trafegue informações do SQL e que conexões possam ser estabelecidas através deste protocolo, vamos liberá-lo no SQL Server, utilizando uma ferramenta disponível na instalação das ferramentas de administração. A ferramenta é o SQL Server 2005 Surface Area Configuration. Esta ferramenta por padrão, encontra-se na pasta Configuration Tools do SQL Server 2005. Nesta ferramenta, utilizaremos os recursos de Surface Area Configuration for Services and Connections. Esta configuração permite agora, que a instância selecionada receba conexões locais e remotas, as conexões remotas serão somente por TCP/IP. A opção Using both TCP/IP and named pipes também poderia ser sido utilizada, sem problemas. Continuando com a configuração do TCP/IP, vamos utilizar agora outra ferramenta, SQL Server Configuration Manager. Nesta ferramenta utilizaremos o recurso SQL Server 2005 Network Configuration, que se encontra no menu da esquerda. Ao expandir este item, encontramos o Protocols for SQL2005. Ao clicar nele, algumas opções se abrirão do lado direito da tela. Nas opções disponibilizadas, devemos deixar o protocolo TCP/IP com status de Enabled. Para fazer isso, clique com o botão direito do mouse em TCP/IP e vá em Enabled. Após isso, ele aparecerá configurado. Depois de configurar o status para Enabled, mais duas verificações devem ser feitas nas propriedades do protocolo TCP/IP. Para acessar estas configurações, clique com o botão direito do mouse em TCP/IP e em seguida em Propriedades. Uma tela com duas abas superiores se abrirá. A primeira aba Protocol, deve ficar com a propriedade Enabled configurada para Yes. Na segunda aba, IP Addresses, devemos garantir que as propriedades Active e Enabled estejam configuradas para Yes. Após garantirmos estas configurações, clicamos em OK para salvar nossas alterações. As alterações que foram feitas nestas duas ferramentas são úteis para garantir que a instância do SQL Server selecionada possa receber conexões remotas e que o protocolo remoto de conexão é o TCP/IP. Passo 3: Para iniciar o serviço do SQL Server Browser, utilizaremos novamente a ferramenta SQL Server Configuration Manger. Para acessar a área que controla os serviços do SQL Server, no menu da esquerda, será utilizado o item SQL Server 2005 Services. Na parte direita da tela, os serviços relacionados ao SQL Server são apresentados. O serviço SQL Server Browser encontra-se com seu State configurado para Stopped. Para iniciar o serviço, clique com o botão direito do mouse no serviço e em seguida clique em Start. Este processo levará alguns instantes, e o State antigo passará a ser Running. Passo 4: Para que as conexões remotas funcionem no SQL Server 2005, o Firewall da rede deve ter exceções para as instâncias do SQL Server 2005 e o serviço do SQL Server Browser. Para exemplificar, colocaremos as exceções no Firewall do próprio Windows. Caso você utilize outro Firewall, você deve ler sua documentação para realizar o procedimento de liberação dos programas utilizados. O Firewall do Windows está presente nas instalações do Windows XP com Service Pack 2 ou superior. Para acessar o Firewall do Windows, vá em Iniciar > Painel de Controle > Firewall do Windows ou digite firewall.cpl em Iniciar > Executar e clique em OK. A liberação no Firewall deve ser feita para cada instância que terá suas conexões remotas permitidas. Realizar estas exceções em cada instância do SQL Server é necessária pelo fato de ser permitido instalar diversas instâncias do SQL Server em um mesmo servidor. Cada instalação do SQL Server é chamada de instância, e cada instância pode ter quantos Bancos de Dados forem necessários, podendo ser repetidos ou não em uma instância ou outra. Para colocar uma instância do SQL Server nas exceções do Firewall, devemos abrir a aba Exceções do Firewall do Windows, clicar em Adicionar Programa, procurar o arquivo SqlServr.exe que por padrão, encontra-se na pasta C:\Arquivos de Programas\Microsoft SQL Server\MSSQL.1\MSSQL\Binn. A pasta MSSQL.1 é a pasta referente à instância 1 do SQL Server. Se for colocar uma exceção para uma segunda instância do SQL, o arquivo SqlServr.exe deve ser localizado na pasta MSSQL.2. Para colocar uma exceção ao serviço do SQL Server Browser, devemos seguir os mesmos passos que percorremos para colocar exceção à instância do SQL Server, a única diferença será procurar o arquivo SqlBrowser.exe que por padrão está na pasta C:\Arquivos de Programas\Microsoft SQL Server\90\Shared. Estes passos apresentados auxiliam a conexão remota com o Servidor de Banco de Dados através de máquinas clientes. Podemos ver que seguindo os passos corretamente, o acesso de aplicações e de ferramentas administrativas deixou de ser exclusivamente da máquina do Servidor de Banco de Dados, e passou a ter acessos liberados para outras máquinas da LAN (Local Area Network). Lembrando que, para acessar uma instância do Banco de Dados, você terá que colocar um usuário e senha válidos para realizar a conexão. Até a próxima. |
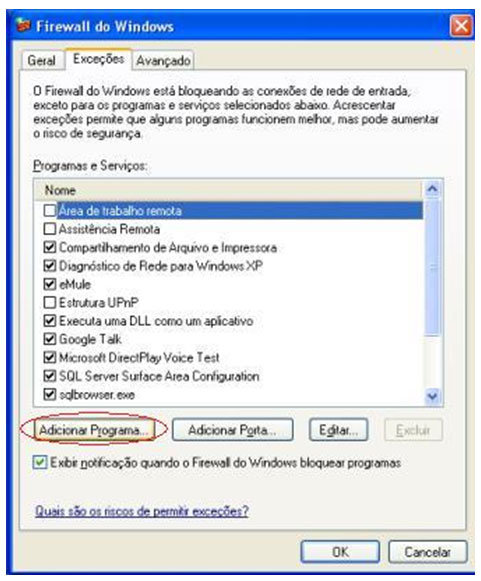
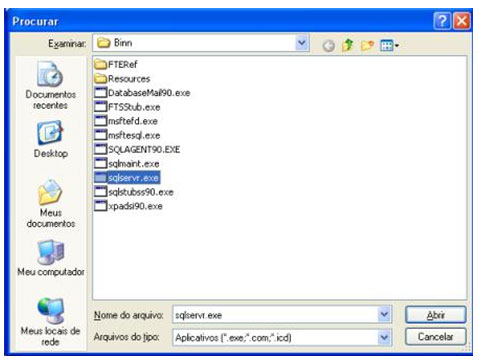
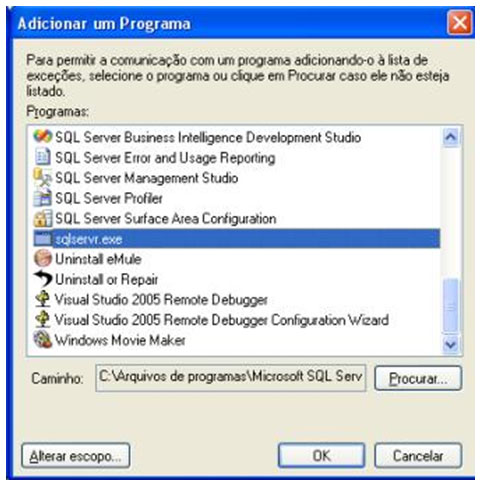
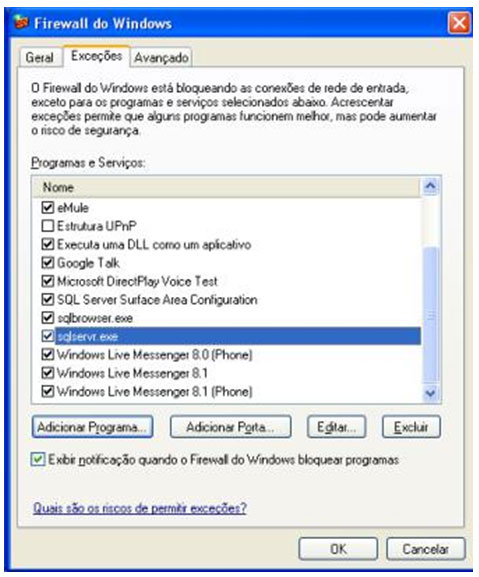
sábado, julio 11, 2009
miércoles, julio 01, 2009
La verdad sobre la minería de datos - 5
Página 5 de 5
Conclusión
Conclusión
Es esencial presentar el campo de trabajo para el complejo proceso de minería de datos. Ello incluye un entendimiento profundo de las entidades de datos empresariales y sus relaciones. Adicionalmente, este no debe ser un proceso que se lleve a cabo una sola vez. En su lugar, se debe aplicar iterativamente y periódicamente se debe revisar y dar mantenimiento a la información habilitada. Cuando se aplica apropiadamente, la minería de datos puede descubrir conocimiento, el "oro” empresarial.
Anna Mallikarjunan es miembro del grupo de investigación y desarrollo de TEC. Es la responsable del análisis y desarrollo del software de apoyo en las decisiones de TEC así como las herramientas de inteligencia de negocios, BI. Con más de cuatro años de experiencia en análisis empresarial, diseño y desarrollo de BI, incluyendo almacenamiento de datos; extracción, transformación y carga (ETL); procesamiento analítico en línea (OLAP); reportes; y desarrollo de aplicaciones personalizadas.
Mallikarjunan ha tenido posiciones tales como, directora de desarrollo de aplicaciones de un grupo de .NET, almacenamiento de datos, y profesional de BI para una empresa de menudeo de ropa. En este trabajo, fue responsable del mantenimiento, desarrollo y soporte de aplicaciones Windows y Web-based, así como almacenamiento operacional de datos, data marts y aplicaciones BI.
Mallikarjunan tiene un BSc en ciencias de la computación de la universidad de Madras (India) y un MSc en ciencias de la computación de la universidad de Anna in Madras, India.
La verdad sobre la minería de datos - 4
Página 4 de 5

1. Evaluación
El paso final es la evaluación del modelo de minería de datos. Una perspectiva prudente para la minería de datos es crear varios modelos. Esto se puede llevar a cabo aplicando varios algoritmos al mismo grupo de datos, o creando varios modelos sincronizando el mismo algoritmo hasta lograr el nivel de exactitud deseado. El resultado de las predicciones en el modelo puede ser comparado con resultados conocidos para lograr una medida de exactitud. Se recomienda separar los datos usados en la evaluación, de los datos en la habilitación del modelo.
Una gráfica de resultados acumulados es una de las múltiples técnicas de prueba de exactitud del modelo. En la gráfica de resultados acumulados, se mide la exactitud del modelo contra un valor elegido por el usuario. Por ejemplo, el valor elegido como objetivo puede ser el porcentaje de clientes que responderán a una campaña de correo electrónico. La línea base (o modelo aleatorio) siempre indica que un porcentaje X del objetivo, será alcanzado con un porcentaje X de datos. Ello indica los resultados de una campaña para la cual los usuarios son seleccionados aleatoriamente, en lugar de usar un modelo de minería de datos. Usando las predicciones del modelo, el porcentaje de respuestas positivas es mapeado con el porcentaje de datos seleccionados para crear una gráfica de sustentación. La siguiente gráfica ilustra el ejemplo que se da a continuación.
Mientras más cerca este la curva de sustentación del modelo ideal, mejor será la exactitud de la capacidad de predicción del modelo, y consecuentemente la distancia entre la línea base y la curva de sustentación será mayor.
Proveedores de sistemas para la minería de datos
SAS es un líder en el mercado de la minería de datos con un record impresionante de implementaciones exitosas. Su Enterprise Miner ofrece una amplia gama de análisis predictivos y formas de visualización. El producto contiene los procesos de minería de datos de SAS llamados SEMMA: muestreo (extrayendo ejemplos representativos que puede ser manipulados fácilmente y particionando los datos para la habilitación y las pruebas); exploración (búsqueda de tendencias o patrones inesperados por medio de técnicas estadísticas o medios visuales); modificación (procesamiento iterativo de datos enfocado en información relevante e inclusión periódica de datos); modelado (aplicando algoritmos de minería de datos para generar pronósticos); y evaluación (pruebas para comprobar la exactitud del modelo).
SPSS ofrece una variedad de productos para el análisis estadístico y la minería de datos. El PASW Modeler provee funcionalidades avanzadas de análisis y visualización. El producto promete aparentemente su integración con la infraestructura de los sistemas existentes de TI, y usa múltiples hilos, clustering y contiene algoritmos para alto rendimiento y escalabilidad. SPSS ofrece una amplia gama de algoritmos, además de minería Web y análisis de pruebas como productos adicionales.
Angoss Software ofrece una solución de análisis de cliente bajo demanda enfocada en las estrategias de ventas y mercadeo. Su KnowledgeSEEKER provee visualización para la exploración de datos; y su KnowledgeSTUDIO representa su herramienta para el modelado, con acceso a una variedad de algoritmos incluyendo árboles de decisión, regresión y clustering.
Microsoft ha realizado un paso significativo en la arena de la minería de datos, con el lanzamiento de SQL Server 2005. Es uno de los componentes de Microsoft BI suite. Este producto incluye varios algoritmos para la minería de datos desarrollados en colaboración entre el grupo de investigación de Microsoft y el grupo de SQL Server. La minería de datos de SQL Server se integra con otras partes del producto BI: servicios de análisis, servicios de integración y servicios de reportes.
La verdad sobre la minería de datos - 3
Página 3 de 5

Fig. 2. Training el modelo de minería de datos 
Fig. 3. Pronósticos a partir del modelo de minería habilitado
| Algoritmo | Descripción |
| Reglas de asociación | Este algoritmo ayuda a descubrir elementos que están asociados. Una implementación común de este algoritmo es el análisis de la cesta de compras, donde se responde a la pregunta "¿si un cliente compra el artículo A y B, que otro artículo tenderá a comprar?” por medio de el examen de las asociaciones entre A y B con otros artículos comprados en el pasado. |
| Clustering | El Clustering crea grupos de objetos de datos basados en su similitud. Los objetos dentro de un cluster son similares a sí mismos y diferentes a los objetos de otros clusters. Clustering tiene una extensa aplicabilidad: en biología para el desarrollo de taxonomías; en los negocios sirve para agrupar clientes basados en su comportamiento, en geografía se usa para agrupar lugares. |
| Arboles de decisión | Los árboles de decisión son estructuras donde una rama divide el grupo de datos para particionar su distribución. Cada rama está basada en un atributo que genera una división significativa en la información. Se pueden realizar pronósticos aplicando los valores del nuevo atributo al árbol de decisiones. |
| Bayes simples | Los algoritmos Bayes tienen un método sistemático de aprendizaje basado en la evidencia. Allí se combinan probabilidades condicionales e incondicionales para calcular las probabilidades de una hipótesis. |
| Regresión | La Regresión ayuda a descubrir la dependencia del valor de un atributo con respecto a otros atributos dentro de la misma entidad u objeto. La regresión es similar a los árboles de decisión en cuanto a su contribución para clasificar datos, pero predice atributos continuos, en lugar de separados. |
| Series de tiempo | Las series de tiempo representan datos en varios intervalos de tiempo o cualquier otro indicador cronológico. Este se usa para pronosticar valores futuros como la demanda y el tráfico de un sitio Web, usando técnicas en auto regresión (una rama del análisis regresivo dedicada al análisis de series de tiempo) y árboles de decisión. |
La habilitación del modelo involucra correr el algoritmo con datos históricos (conocido también como habilitación de datos). El algoritmo analiza y encuentra relaciones entre los datos. El resultado son patrones que se almacenan en el modelo de habilitación de datos para crear un modelo de minería de datos. La habilitación puede ser un proceso largo, ya que involucra la aplicación del algoritmo de minería a vastas cantidades de datos, de manera interactiva.
- De los datos usados en la evaluación, sabemos que el 40% de los datos representan el objetivo. Este es el modelo ideal.
- Usando las predicciones del modelo, se puede observar que el modelo puede alcanzar 100% del objetivo con el 90% de los datos.
- Si usamos el modelo de minería (ver la grafica coeficiente de sustentación), podemos alcanzar el 36% de los datos (Ejemplo: 90% de 40%).
- Si elegimos los clientes aleatoriamente (véase la línea base), solo alcanzaremos el 20% de los datos (Ejemplo: 50% de 40%)
La predicción o pronóstico involucra un nuevo grupo de datos a través del modelo habilitado. Para crear los pronósticos, se aplican las reglas y los patrones creados en la habilitación. Los pronóstico se pueden realizar en la medida en que entra nueva información y en tiempo real. El modelo habilitado de minería representa todos los valores posibles de atributos relevantes e incluye un valor de probabilidad asociado a cada combinación. Los pronósticos pueden implicar el proceso de determinar valores diferenciados o etiquetas de clases (como en las técnicas de clasificación), o los pronósticos de valores continuos (como en las técnicas de regresión).
La verdad sobre la minería de datos - 2
¿Por qué no OLAP o estadística?

Fig. 1. Creación del modelo de minería de datos
La discusión sobre los procesos de la minería de datos en este articulo, está centrada en la creación de los modelos y su evaluación. El modelo constituye el corazón o centro de la minería de datos. El primer paso es la creación del modelo, a través de la selección de datos importantes para el objetivo. Por ejemplo, si un ejercicio de investigación sobre educación necesita estudiar el rendimiento de los estudiantes a través de varias ciudades en un estado o departamento especifico, solo los datos de ese estado son relevantes. Así mismo, si el objetivo es estudiar las relaciones entre la asistencia y la ocupación y salario de los padres, los atributos importantes incluirán la asistencia de la entidad estudiantes (sin las calificaciones o niveles) y la ocupación y salario de la entidad padres (sin importar edad o grupo cultural).
Una vez establecido el objetivo del ejercicio de la minería de datos, se debe elegir la función o algoritmo. El modelo se estructura para almacenar los resultados encontrados por el algoritmo. La siguiente tabla señala a grandes rasgos, los algoritmos más comúnmente usados (una discusión en detalle de estos algoritmos, se sale del marco de este artículo).
La minería de datos incluye técnicas avanzadas para comprender los datos que superan la habilidad de OLAP (online analytical processing). Las herramientas OLAP proveen los medios para realizar análisis multidimensionales por medio de poderosos algoritmos para agrupar y resumir datos. Mientras OLAP le permite visualizar las ventas de ciertos productos dentro de una región y periodo específicos, la minería de datos puede descubrir relaciones entre varios atributos en los datos y deducir porqué las ventas han bajado en una región sobre un periodo de tiempo. OLAP y la minería de datos son usados en conjunto y encontramos que estas dos tecnologías coexisten alegremente en los ambientes de almacenamiento y BI.
La comparación entre la estadística y la minería de datos, no están directa como parece. La razón principal es que ellas pertenecen a dos ramas de estudio separadas, las matemáticas y las ciencias de la computación. Mientras la minería se refiere a la explotación de grandes cantidades de datos (gigabytes o terabytes), la estadística se enfoca en la confirmación de hipótesis establecidas en un modelo y provee evidencia bien para apoyar la teoría o establece la falta de evidencia. Consecuentemente, la mayoría de los paquetes estadísticos no manejan la cantidad de información que se usa normalmente en los procesos de minería de datos.
Arquitectura de los sistemas de minería de datos
Al describir la arquitectura de un sistema de minería de datos, suponemos la presencia de un almacén o bodega de datos que contienen los datos de la organización. Aunque la minería de datos se puede aplicar a una amplia gama de fuentes de datos, es mejor iniciar con un almacén de datos en el que los hechos y las dimensiones se han identificado, y un marco de limpieza de datos establecido con el fin de garantizar una buena calidad de los mismos.
1. La base de conocimientos:
La corteza de un sistema de minería de datos es la base de datos de una organización. Este es el campo de conocimiento que describe los datos de una organización. Él incluye jerarquías de conceptos que organizan atributos o atribuyen valores de conceptos o clases específicas hacia generales. Los conceptos pueden ser implícitos, como las direcciones que se describen con número, calle, cuidad, estado y país. Las jerarquías de conceptos pueden ser creadas por medio de la organización de los valores. Un ejemplo de dicha jerarquía, comúnmente conocida como grupo predefinido de jerarquías, es el tamaño de la empresa, que puede ser definido como micro (<> 500 empleados)
Los niveles de interés constituyen otro ejemplo del campo de los conocimientos. Estas medidas ayudan a clasificar o filtrar las normas que se generan a partir de los datos para determinar los patrones que serán más útiles para un negocio. Los niveles de interés pueden incluir medidas objetivas que se identifican estadísticamente y medidas subjetivas que se derivan de las creencias al respecto de las relaciones de los datos ayudando a evaluar el grado de probabilidad de que un evento ocurra o no, segun los resultados obtenidos a partir de minería de datos. La base de conocimientos es un elemento esencial en todas las etapas del proceso de minería de datos.
2. El proceso de la minería de datos: La discusión sobre los procesos de la minería de datos en este articulo, está centrada en la creación de los modelos y su evaluación. El modelo constituye el corazón o centro de la minería de datos. El primer paso es la creación del modelo, a través de la selección de datos importantes para el objetivo. Por ejemplo, si un ejercicio de investigación sobre educación necesita estudiar el rendimiento de los estudiantes a través de varias ciudades en un estado o departamento especifico, solo los datos de ese estado son relevantes. Así mismo, si el objetivo es estudiar las relaciones entre la asistencia y la ocupación y salario de los padres, los atributos importantes incluirán la asistencia de la entidad estudiantes (sin las calificaciones o niveles) y la ocupación y salario de la entidad padres (sin importar edad o grupo cultural).
Una vez establecido el objetivo del ejercicio de la minería de datos, se debe elegir la función o algoritmo. El modelo se estructura para almacenar los resultados encontrados por el algoritmo. La siguiente tabla señala a grandes rasgos, los algoritmos más comúnmente usados (una discusión en detalle de estos algoritmos, se sale del marco de este artículo).
La verdad sobre la minería de datos - 1
Tomado de:
http://www.technologyevaluation.com/es/Research/ResearchHighlights/BusinessIntelligence/2009/06/research_notes/es/TU_BI_AM_06_15_09_1.asp
http://www.technologyevaluation.com/es/Research/ResearchHighlights/BusinessIntelligence/2009/06/research_notes/es/TU_BI_AM_06_15_09_1.asp
La verdad sobre la minería de datos
- Junio 24, 2009
Página 1 de 5
La implementación de un sistema de inteligencia empresarial (BI, Business Intelligence) se puede ver desde la perspectiva de dos capas. La primera comprende los reportes estándares, reportes especiales, análisis multidimensionales, tablero de mandos, scorecards y alertas. La segunda capa se encuentra más comúnmente en aquellas organizaciones que han construido y madurado la primera capa. El análisis avanzado de datos por medio de modelos predictivos y pronósticos define esta capa; en otras palabras, la minería de datos.
La minería de datos tiene un alcance y aplicaciones muy amplias. Puede ser utilizada en cualquier situación donde se requiere encontrar conocimiento en vastas cantidades de datos. A través de este articulo, la palabra conocimiento es usada para referirse a patrones significativos derivados de técnicas de minería de datos que pueden estimular los objetivos de una organización, como los ingresos, tráfico del sitio Web, cultivo de campos de información y mejorar los estándares de salud. Los espacios de minería de datos reúnen técnicas estadísticas, el aprendizaje automático o intuitivo de las máquinas (el diseño y desarrollo de algoritmos que permiten a los sistemas aprender y mejorar su propio rendimiento basados en sus propias experiencias); redes de trabajo neutrales (modelos computacionales o matemáticos basados en un sistema nervioso); tecnología de base de datos; tecnología de alto rendimiento (el uso de supercomputadoras o clústeres); análisis de datos espaciales (técnica para estudiar entidades usando su espacio topológico, geométrico o características geométricas), por nombrar algunas. La minería de datos en un área de estudio compleja aún considerada esotérica y difícil de implementar en algunos ambientes BI.
La minería de datos se refiere al proceso de extracción de patrones escondidos en grandes cantidades de datos. El término minería es con frecuencia utilizado como analogía como en el caso de la minería de oro o de carbón; sin embargo, el producto final de la minería de datos no son los datos, es el conocimiento. La minería de datos se aplica en una gran variedad de situaciones, pero presentamos aquí los escenarios empresariales más comunes en los cuales se presenta como una solución:
* Explotación de datos: Cuando la cantidad de información crece significativamente, solo los modelos estadísticos especializados, pueden ayudar a desenmascarar patrones importantes; en esta situación, los análisis simples y multidimensionales no serán suficientes.
* Comportamiento predictivo: Estas son situaciones donde las organizaciones necesitan predecir el comportamiento de los clientes. Este tipo de análisis permite identificar a los clientes en riesgo de cambiar hacia la competencia. Dentro de una población de animales se puede llevar a cabo modelado de enfermedades basado en información relevante sobre la especie, realizando predicciones y estimando el riesgo de enfermedad.
* Ventas cruzadas: Comúnmente conocido como análisis de la cesta de mercado, la minería de datos puede dar información sobre los patrones de ventas cruzadas. Las tiendas en línea de libros como Amazon.com, usan esta técnica para sugerir libros relacionados con el que se está buscando o comprando.
* Formaciones taxonómicas: La minería de datos puede ser aplicada en situaciones donde los datos de entrenamiento (los datos usados para entrenar el modelo de minería) están perdiendo algún tipo de etiqueta. Las etiquetas se usan para conceptualizar datos. Por ejemplo, en el análisis que examina las relaciones entre las ventas y las temporadas, estas últimas pueden ser categorizadas como primavera, verano, etc. El clustering o la segmentación es el proceso de particionamiento de datos en clases o incluso en jerarquías de clases, para los cuales los miembros de un grupo tienen características similares.
* Pronósticos: Para estimar valores futuros de entidades, se debe aplicar técnicas de pronósticos. Por ejemplo, pronosticando la demanda futura de sus productos, un fabricante puede planear su producción.
Suscribirse a:
Comentarios (Atom)